Mit SRE ein perfektes Gleichgewicht zwischen Agilität und Stabilität erreichen
Wenn Sie einen kundenorientierten Ansatz für Ihre Lösungen wünschen, sollten Sie hierfür Methoden wie Site Reliability Engineering (SRE) in Betracht ziehen.
Wir bei Skaylink konzentrieren uns verstärkt auf DevOps und es ist uns ein Anliegen, Aufgaben kundenorientiert zu lösen. Unser vorrangiges Ziel besteht darin, die Interessen von Entwickler*innen und Betriebsverantwortlichen unter einen Hut zu bringen – auch dann, wenn es Konflikte gibt (beispielsweise der Wunsch nach neuen Funktionen ohne Einschränkungen, der dem Widerwillen, etwas in einem gut funktionierenden System zu ändern, gegenübersteht).
Site Reliability Engineering
Google hat SRE entwickelt und veröffentlicht, um die eigenen großen Systeme verwalten zu können. Die Grundlagen und Vorgehensweisen von SRE als technisches Werkzeug wurden allerdings von vielen weiteren Unternehmen übernommen, um den zuverlässigen Betrieb ihrer Software-Systeme zu verbessern. SRE beschreibt grundsätzlich eine Reihe an Vorgehensweisen und Grundlagen, mit denen Software Engineering und Betrieb miteinander verknüpft werden. Mithilfe von Automatisierung, Überwachung, Vorfallsbearbeitung und kontinuierlicher Verbesserung werden die Zuverlässigkeit, die Leistung und die Verfügbarkeit von komplexen Software-Systemen sichergestellt.
Site Reliability Engineering unterstützt Unternehmen bei der nachhaltigen Gestaltung des zuverlässigen Betriebs ihrer Systeme. Dabei ist es wichtig, ein gutes Gleichgewicht zwischen Agilität und Stabilität im jeweiligen Unternehmen zu erreichen.
Die SRE-Teams betreuen folgende Bereiche:
Verfügbarkeit / Stabilität / Latenzzeit / Leistung / Effizienz / Change Management / Überwachung / Notfallbearbeitung und Kapazitätsplanung der Dienste
Damit sich das Team auch bei Großprojekten um diese Bereiche kümmern kann, haben wir uns das Ziel gesetzt, alle repetitiven Aufgaben zu automatisieren oder ganz zu streichen. Das SRE-Team konzentriert sich verstärkt darauf, dass das Systemdesign zuverlässig funktioniert, und zwar auch dann, wenn häufige Updates von Entwicklerteams eingespielt werden.
Damit sich das SRE-Team auch auf ein sich in Entwicklung befindliches System einstellen kann, muss eine umfangreiche Überwachung des Systems möglich sein. Dafür müssen ausreichend Daten im System gespeichert werden, die für ausführliche Untersuchungen genutzt werden können. Auf diese Weise kann das SRE-Team laufend neue User-Flows beurteilen und projektkritische Prozesse überwachen.
Agilität oder Stabilität
In der Vergangenheit sorgte die Diskrepanz zwischen Entwicklung und stabilem Betrieb häufig für Konflikte. Man war sich nicht einig, was nun für Kunden wichtiger ist: Agilität, um neue Funktionen einführen zu können, oder die Aufrechterhaltung der Stabilität in einem System.
Mit dem SRE-Konzept können wir dieses Dilemma genauer betrachten. Dazu nutzen wir Service Level Indicators (SLIs), Service Level Objectives (SLOs) sowie das sich daraus ergebende Fehlerbudget.
Die SLIs dienen der Überwachung von wichtigen User-Flows, beispielsweise bei einer IoT-Lösung. So kann es vorkommen, dass Benutzer*innen einen Sensor installieren und in einem Administrationspanel bestätigen, dass dieser aktiv ist. Zu den SLOs gehören Regeln bezüglich der von den Benutzer*innen erwarteten Latenzzeit, Verfügbarkeit und Fehlerspanne.
Das SRE-Team und das Unternehmen können die SLOs für einen gemeinsamen Austausch nutzen und so eine Einigkeit bezüglich konkreter Zahlen für Betriebsbereitschaftszeiten und Leistung erlangen. Die Differenz zwischen den gemessenen SLIs und den vorgegebenen SLOs wird Fehlerbudget genannt. Ist die Leistung besser als vereinbart, dürfen die Entwicklerteams neue Funktionen so oft sie möchten einführen. Sobald das Budget aber negativ ausfällt, ist das SRE-Team dafür verantwortlich, sämtliche Neueinführungen zu stoppen, das Problem zu analysieren und Störfaktoren zu beseitigen – oder alternativ dem Entwicklerteam die Aufgabe zu erteilen, diese zu entfernen. Grundsätzlich bedeuten negative SLOs bei einem Projekt, dass man sich verstärkt auf die Qualität konzentrieren muss. Der Interessenkonflikt zwischen Betrieb und Entwicklung kann entschärft werden, indem man sich danach richtet, ob die vereinbarten SLOs positiv oder negativ ausfallen.
Um das Fehlerbudget genauer definieren zu können, müssen wir festlegen, wie viel „Instabilität“ innerhalb eines vereinbarten Zeitraums zulässig ist. Dieser Begriff ist wichtig, denn sämtliche Implementierungen bergen ein Risiko für Instabilität. Selbst die größten Unternehmen, wie z. B. Microsoft, bringen manchmal Neuerungen heraus, die trotz aller Tests und Best Practices mit einem Systemausfall enden.
Vielleicht wirft man dem SRE-Team vor, dass es sich nur auf den User-Flow konzentriert, anstatt auch auf die Verfügbarkeit und Antwortzeit zu achten. Dabei kann der User-Flow aber auch aus einer geschäftlichen Perspektive wie Einnahmen oder Kündigungen (Verlust von Kunden) gesehen werden. Betrachten wir dazu das folgende Beispiel, bei dem wir eine Machine-Learning-Lösung für die Benutzerempfehlungen verwenden.
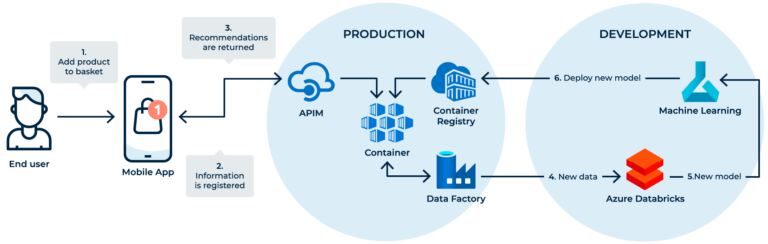
In der Abbildung ist eine Pipeline dargestellt, die Benutzeraktivitäten und wöchentliche Käufe als Grundlage nutzt und diese für die Aktualisierung einer Machine-Learning-Lösung für Empfehlungen kombiniert. Fällt diese Pipeline aus, stützt sich die Lösung auf veraltete Daten. Eventuell ist der*die Benutzerin an den Empfehlungen eventuell gar nicht mehr interessiert. Dies kann die Einnahmen eines Unternehmens nach und nach beeinflussen. In einem solchen Fall könnten die Konsequenzen für das Unternehmen aus sinkenden Konvertierungsraten beim Verkauf oder einem größeren Verlust an Kunden bestehen. Daher müssen diese User-Flows eines Unternehmens unbedingt überwacht werden.
Die Bedeutung der SRE-orientierten Teams
Es ist nicht wichtig, viele SLOs zu definieren, sondern es geht vielmehr darum, die richtigen SLOs festzulegen. Ein guter Hinweis darauf, ob ein SLO relevant ist oder nicht, ist: „Wenn Sie eine Diskussion bezüglich der Priorisierung eines bestimmten SLO nie gewinnen, ist es wahrscheinlich nicht so wichtig, das SLO zu behalten.“
Ein SRE-Team kann für ein Unternehmen großen Mehrwert bedeuten, da Unternehmensanforderungen standardisiert und in einen Code verpackt werden können. Das SRE-Team besteht aus Entwickler*innen, die Infrastruktur, CI/CD-Pipelines und Unternehmensfunktionen verbessern.
Für uns hat das SRE-Team u. a. kontinuierlich strukturelle Verbesserungen des Projekts bewirkt und so Mehrwert geschaffen. Auf diese Weise können andere Entwicklerteams auch rascher Ergebnisse erzielen, denn die dafür benötigten technischen Anforderungen, die das gesamte Projekt betreffen, werden von einem dafür vorgesehenen Team bereitgestellt. Bei verschiedenen Projekten hat unser SRE-Team bewiesen, dass es Mehrwert generieren kann. Es hat Belastungstests durchgeführt, SLOs überwacht und als CoE-Team fungiert sowie fachbereichsübergreifende Funktionen für Entwicklerteams implementiert. Dadurch konnten wir Probleme und Engpässe identifizieren, noch bevor sie für die Benutzer*innen zum Problem wurden.
Der wichtigste Arbeitsbereich eines SRE-Teams besteht letztendlich darin, dass jeder unbeabsichtigte Vorfall sofort identifiziert und priorisiert werden kann. Das bedeutet aber nicht, dass immer das SRE-Team das ursächliche Problem lösen muss. Dieser Teil der Arbeit kann an andere Teams abgegeben werden. Aber natürlich wird man sich vorrangig darauf konzentrieren, die Situation so schnell wie möglich zu lösen und sicherzustellen, dass alles funktioniert. Dabei sollte stets die zukünftige Entwicklung und nicht das Rückgängigmachen der Änderungen priorisiert werden, um die Agilität des Projektes zu bewahren.
Wie beginnt man am besten?
Um noch einmal zu unterstreichen, welchen konkreten Mehrwert SRE-Teams liefern können, möchte ich die folgenden 3 Punkte zusammenfassen:
- Besseres Verständnis für das sich gerade in der Entwicklung befindende System
- Schnelles Reagieren bei Problemen sicherstellen
- Deutliche Kommunikation in Bezug auf Anforderungen und Leistung für das Unternehmen
Um dies in einem Unternehmen erreichen zu können, ist es für uns wichtig, das System systematisch und automatisch zu testen. Dabei kommen sämtliche Testarten zum Einsatz: Einheitstests, Integrationstests, End-to-End-Tests, Belastungstests und schließlich Chaos Engineering. Auf diese Weise erhalten Sie einen Überblick darüber, wie gut Sie auf Probleme und Katastrophen vorbereitet sind. Nur aufgrund unserer soliden Erfahrung auf den Gebieten DevOps und SRE können wir all das gemeinsam mit unseren Kunden erreichen.
Unseren Releases wird großes Vertrauen entgegengebracht und wir haben ein hohes Kontrollniveau erzielt. Wir beseitigen alle manuellen Vorgehensweisen und Schritte, die für die Implementierung notwendig sind, und vertrauen voll und ganz auf die Automatisierung mithilfe von CI/CD-Pipelines.
SLA-Verträge
Aufmerksame Leser haben sicher bemerkt, dass wir noch gar nicht über Service Level Agreements (SLA) gesprochen haben, mit denen die meisten vertraut sein werden. Ein SLA ist ein ausdrücklicher oder impliziter Vertrag mit Ihren Benutzer*innen, in dem die Konsequenzen der Erfüllung (oder Nichterfüllung) festgehalten sind. Ein SLA ist eine Beschreibung des gesamten Systems auf der Grundlage einer Metrik, die sich an die Benutzer*innen richtet. In diesem Zusammenhang kann es aber schwierig für das Team sein, konkrete Maßnahmen zu treffen. Die SLOs sind die Ziele, die das Team erreichen muss, um den Vertrag (SLA) zu erfüllen. Und natürlich achtet das SRE-Team noch auf die genauen Zahlen, den SLIs. Das SRE-Team wird normalerweise nicht in die Ausarbeitung eines SLA miteinbezogen, da ein SLA stark von den jeweiligen Unternehmens- bzw. Projektentscheidungen abhängt.
Post-Mortem-Kultur ohne Schuldzuweisungen
Trotz all dieser Bemühungen kann manchmal leider nicht vermieden werden, dass es bei der Entwicklung zu Problemen kommt. Um das Risiko zu minimieren, dass ein ähnliches Problem erneut auftritt, haben wir eine Post-Mortem-Kultur entwickelt, die ohne Schuldzuweisungen auskommt. Statt Schuld zuzuweisen, setzen wir auf das Finden der Ursache und die anschließende Lösung.
Wir folgen diesen vier Schritten:
- Problem definieren und beschreiben
- Tests implementieren, die das Problem simulieren
- Lösung finden
- Lösung bei der Entwicklung implementieren
Auf diese Weise können wir sicherstellen, dass das Problem nicht erneut auftritt. Indem wir das Problem definieren, können wir Fehler in unseren Prozessen feststellen, die behoben werden müssen. So erhalten wir ein klares Bild vom Vorfall. Zudem streben wir eine direkte und präzise Kommunikation mit den Stakeholder*innen an. So können wir auch sicherstellen, dass wir eine Lösung für die zugrundeliegenden Ursachen gefunden haben.
Wir sind der Meinung, dass dies eine großartige Möglichkeit ist, die Transformation bei großen Projekten voranzutreiben, unabhängig vom Reifegrad Ihres Unternehmens. Der Mehrwert ist für Sie sofort sichtbar, und die Arbeit kann ohne die üblichen Konflikte und Diskussionen zwischen Development und Operations weitergehen.
Möchten auch Sie gerne SRE nutzen?
Wenn Sie mehr über das volle Potenzial von SRE erfahren wollen oder generell Unterstützung bei der Umstellung Ihrer Entwicklungsabteilung bzw. Ihres Unternehmens zugunsten wirklich agiler Prozesse brauchen, helfen wir Ihnen gerne weiter. Unsere Experten freuen sich über Ihre Nachricht!