Ein typischer Arbeitstag besteht hauptsächlich daraus, Probleme zu lösen: welche(n) Kandidat*in stellen wir ein? Wie lege ich ein neues Nutzerkonto an? Wo finde ich die richtige Dokumentation für den jeweiligen Prozess? Diese Fragen wiederholen sich. Und wir müssen uns eingestehen, dass sie uns in den nächsten Monaten wieder begegnen werden – wenn auch mit leichten Variationen im Kontext und den betreffenden Technologien.
Wäre es nicht wunderbar, wenn wir einfach ChatGPT (oder ein vergleichbares Sprachmodel) fragen könnten: Wie habe ich das Problem das letzte Mal gelöst? Oder noch besser: Wie hat die letzte Person in der Firma dieses Problem gelöst? Wenn sich das für Sie wie eine weit-entfernte Zukunft anhört, liegen Sie falsch: Viele Domain-spezifische Systeme existieren bereits. Die aktuellen Fortschritte in Künstlicher Intelligenz (KI) und insbesondere Natural Language Processing (NLP) ermöglichen es, diese Systeme zu Lösungen zum generellen Finden von Informationen auszubauen.
In diesem Artikel werden wir reale Fälle von Empfehlungs- und Informationsabfragesystemen in Unternehmen untersuchen. Dazu zeigen wir auf, dass die Werkzeuge und Technologien bereits ausgereift sind, um diese Systeme in einer Vielzahl neuer Anwendungsfälle problemlos wiederzuverwenden. Und wir werden Ihnen praktische Vorschläge zur Überwindung der bestehenden organisatorischen Hindernisse und zur Einführung dieser Technologien in Ihrem Unternehmen vorstellen.
Welche Beispiele für Empfehlungs- und Informationsabfragesystemen gibt es schon?
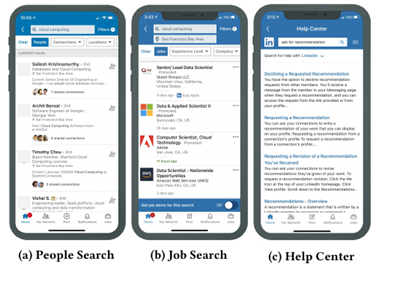
Viele große Unternehmen entwickeln ihre eigenen internen Systeme, um das gesammelte Wissen in ihren Datenbanken zu nutzen. LinkedIn beispielsweise verfügt über eine „Personensuche“, die relevante Mitgliederprofile aufspürt. Dieselben Technologien nutzt das Unternehmen für die Suche nach ähnlichen Stellenangeboten und für Lösungsempfehlungen im Help Center.
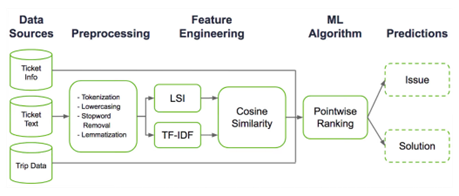
Auch Uber verfügt über ein System für Lösungsvorschläge und Antwortvorlagen in seinem Ticketsystem. Dies hilft Uber bei der Bearbeitung von Hunderttausenden von Tickets, die jeden Tag in mehr als 400 Städten weltweit eingehen. Uber berichtet, dass allein mit diesem Tool die Zeit für die Lösung von Tickets um 10 % gesunken ist.
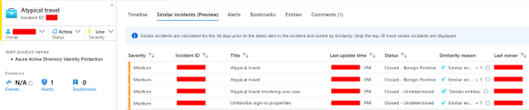
Dies ist jedoch nicht auf unternehmensspezifische Systeme beschränkt. Viele Incident-Management-Lösungen integrieren ähnliche Funktionen. Ein Beispiel hierfür ist Azure Sentinel: Die Software dient zur Verwaltung von Sicherheitsvorfällen. Microsoft hat kürzlich die Funktion „Similar Incidents“ im Preview veröffentlicht. Administrator*innen erhalten nun eine Liste von bereits gelösten Tickets zu ähnlichen Problemen.
Erfahrungen durch Information Retrieval
All dies ist keine Raketenwissenschaft. Schon seit 50 Jahren wird dieses Feld unter dem Namen Information Retrieval (IR) intensiv erforscht. Es ist definiert als die Suche nach unstrukturierten Dokumenten (in der Regel hauptsächlich aus Text bestehend), die einen Informationsbedarf als Teil einer großen Sammlung befriedigen.
Ein Beispiel hierfür ist Google. Websuchen erledigen diese Aufgabe sehr gut. Sie sind das bekannteste Beispiel für ein IR-System. Aber diese Systeme sind noch nicht in gleichem Maße für die unternehmensbezogene, institutionelle und domänenspezifische Suche geeignet. Dieses Szenario begann erst in den letzten Jahren an Bedeutung zu gewinnen.
Mit der Verbreitung großer Sprachmodelle, von denen ChatGPT das bekannteste Beispiel ist, wird die Suche in komplexen Unternehmensdatenspeichern immer einfacher. Außerdem ist das Ökosystem der Big-Data-Tools bereits sehr ausgereift, so dass Infrastruktur- und Data-Engineering-Probleme mit Standardtools gelöst werden können. Aufgrund dieser Faktoren erreicht das Thema, welches ursprünglich nur für Early Adopters relevant war, nun langsam die Mehrheit der Unternehmen.
Mit diesen Tools können Sie anfangen
Wie Sie sich denken können, vereinfachen die jüngsten Fortschritte in der künstlichen Intelligenz die Anwendung von Information Retrieval-Techniken erheblich. Sie verfügen schon von Haus aus über das semantische Verständnis, das vor Jahrzehnten noch ein umfangreiches manuelles Feature Engineering erforderte. Wenn Sie diese Techniken also noch nicht in Ihrer täglichen Arbeit einsetzen, sollten Sie dies ernsthaft in Erwägung ziehen.
Die meisten Industriezweige weisen die in der Einleitung dieses Artikels beschriebenen Merkmale auf: die Lösung sich wiederholender Probleme, die innerhalb weniger Monate viele Male auftreten. Ein intelligentes System könnte die meisten der mit der Problemlösung verbundenen Tätigkeiten mit nur minimaler menschlicher Aufsicht durchführen. Dazu benötigt es nur den Zugang zu digitalen Datensätze, die beschreiben, wie das Problem gelöst wurde. Für den Aufbau solcher Systeme gibt es umfangreiche technologische Grundlagen, auf denen man aufsetzen kann:
- ElasticSearch „das könnte Ihnen auch gefallen“-Funktion: Es handelt sich um eine Abfragemethode in der berühmten Suchmaschine ElasticSearch. Sie ermöglicht es, Dokumente zu finden, die einem vorgegebenen Satz von Dokumenten ähnlich sind.
- Azure Cognitive Search: Suchmaschine von Microsoft. Ähnlich wie ElasticSearch, aber mit vielen Optionen für KI-basierte Erweiterung, plus Integrationen zu vielen anderen Azure-Diensten.
- OpenAI Search: Diese API von OpenAI basiert auf neuronalen Modellen. Sie ermöglicht den semantischen Vergleich zwischen einer Suchanfrage (was Sie suchen) und einer Reihe von Dokumenten (wo Sie suchen).
- Open Capivara: ein Open-Source-Projekt, das ein kognitives Layer für die Suche nach Support-Tickets entwickelt.
Gründe für die schleppende Einführung von Information-Retrieval-Systemen
Aber wenn es so viele verfügbare Werkzeuge gibt… Warum nutzt das dann nicht jedes Unternehmen? Es gibt viele Perspektiven, warum sich Unternehmen mit der Einführung schwertun:
- Aus Sicht von Ingenieur*innen und Entwickler*innen: Die allgemeine Architektur von Information Retrieval-Systemen unterscheidet sich von den meisten anderen Softwares und erfordert spezielles Fachwissen zur Implementierung. Das Gleiche gilt für die Bewertungs- und Testmethoden. Das macht es sehr schwierig, die Korrektheit des entwickelten Systems zu bestätigen.
- Aus Sicht der Nutzer*innen: Die meisten Menschen sind es nicht gewohnt, bei ihrer Arbeit an die „Informationsgewinnung in großen Datenbanken“ zu denken. Sie tun sich daher schwer, die Vorteile von IR-Systemen voll auszuschöpfen. Wenn die Benutzeroberfläche nicht intuitiv ist oder das Verhalten des Systems für die Benutzer*innen nicht klar ist, werden selbst die besten IR-Systeme von den Endbenutzer*innen nicht in großem Umfang angenommen.
- Aus Sicht von Manager*innen und Produktverantwortlichen: Die Integration von IR-Funktionen in ein bestehendes System erfordert nicht nur die technischen Fähigkeiten zur Entwicklung der Funktionen, sondern auch eine strategische Vision davon, wie diese Funktionen einen Mehrwert schaffen und wie ihre Entwicklung priorisiert werden sollte. Oftmals fehlt Manager*innen und Produktverantwortlichen diese Vision und sie ziehen es vor, sich an traditionellere Technologien zu halten.
Bei der Bewältigung dieser Herausforderungen können Sie auf das Fachwissen von Skaylink zählen. Wir verfügen über das praktisches Know-how zur Implementierung von Information Retrieval-Systemen, die Cloud-nativ und zuverlässig sind und – was am wichtigsten ist – Ihrem Unternehmen helfen, die bereits vorhandenen Daten zu nutzen. Sprechen Sie uns an!
Quellen:
- GUO, W. et al. Detext: A deep text ranking framework with bert. CoRR, abs/2008.02460, 2020. Available at: http://dblp.uni-trier.de/db/journals/corr/corr2008.html# Abs-2008-02460.
- MOLINO, P.; ZHENG, H.; WANG, Y.-C. Cota: Improving the speed and accuracy of customer support through ranking and deep networks. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: Association for Computing Machinery, 2018. (KDD ’18), p. 586–595. ISBN 9781450355520. Available at: https://doi.org/10.1145/3219819.3219851
- MANNING, C. D.; RAGHAVAN, P.; SCHÜTZE, H. Introduction to Information Retrieval. Cambridge, UK: Cambridge University Press, 2008. ISBN 978-0-521-86571-5.